OpenAI内部通用大模型已经可以拿到国际数学奥利匹克竞赛金牌:AI推理能力已经接近人类顶级水平
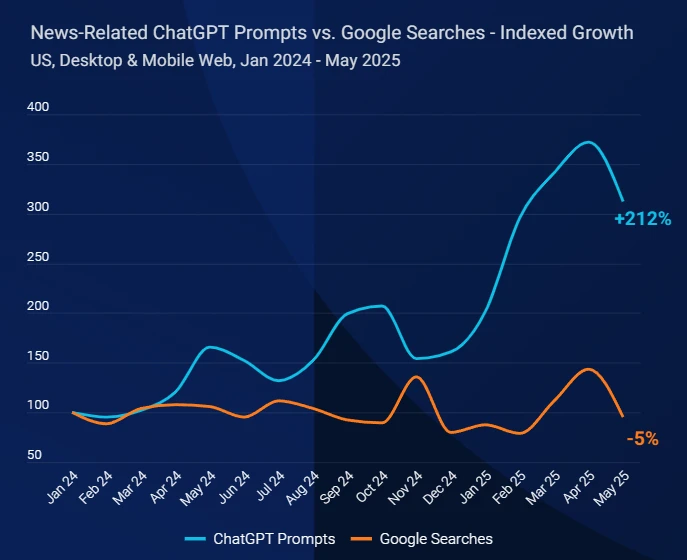
几个小时前,OpenAI的研究人员披露,其一款内部实验性的大语言模型,在模拟的国际数学奥林匹克(International Math Olympiad ,IMO)竞赛2025中取得了金牌水平的成绩。这是一个里程碑式的突破,因为IMO被认为是衡量创造性数学推理能力的巅峰,远超以往任何AI基准测试。这项成就并非通过专门针对数学的“窄”方法实现,而是源于通用人工智能研究的根本性突破,尤其是在处理难以验证的任务和长时间推理方面。