GPT-5.2与Gemini 3.0 Pro、Opus 4.5实测对比:前端页面没有更强
GPT-5.2 刚发布:和 Opus 4.5、Gemini 3.0 Pro 放一起看,怎么选更省心?
OpenAI 刚刚把 GPT-5.2 推上来了。我们在 DataLearnerAI 上把它和 Claude Opus 4.5、Gemini 3.0 Pro(Preview) 放到同一个对比页里,拉齐公开评测与基础规格,做一个“站在真实选择角度”的快速判断。
对比结果页面(完整数据):https://www.datalearner.com/compare/result?modelInputString=739%2C724%2C707
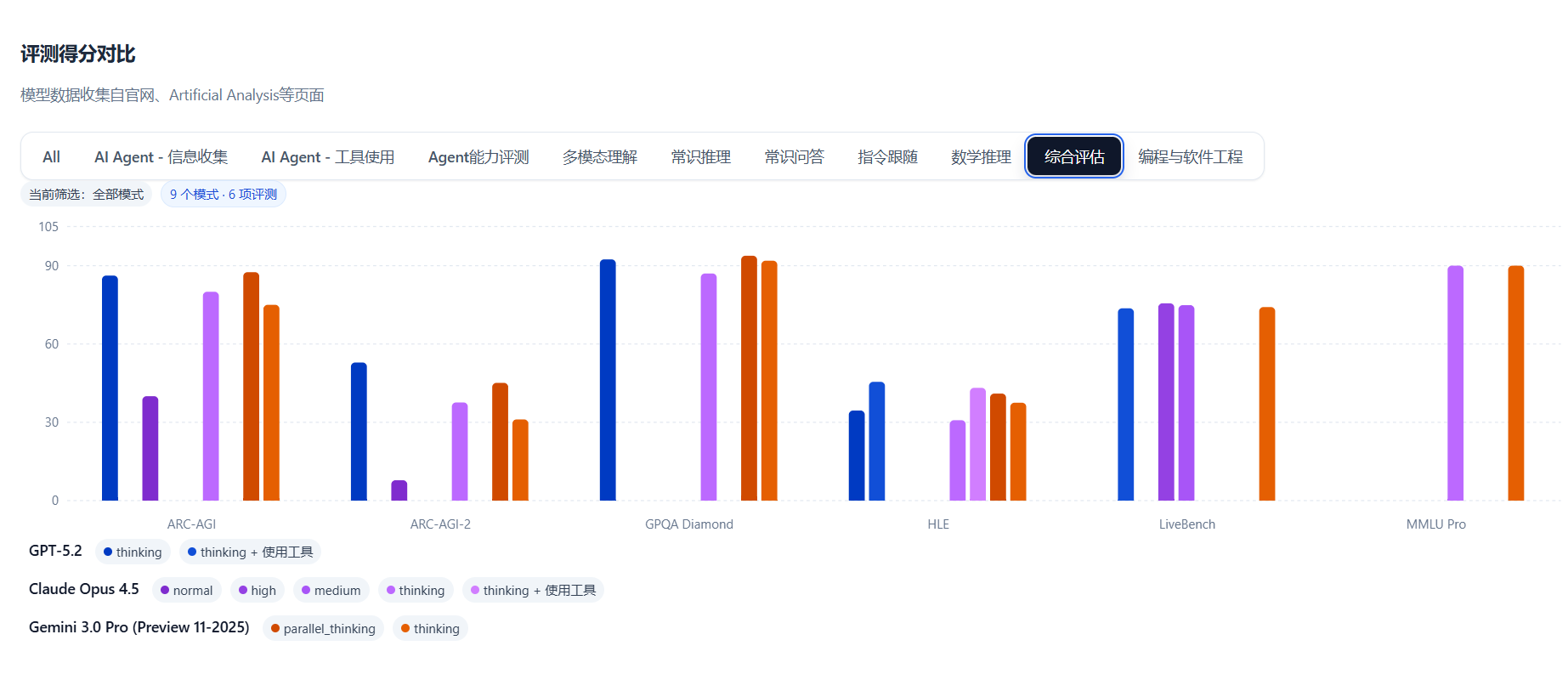
上面这张截图是我们截的综合对比的一小部分(深蓝色是 GPT-5.2)。直观看,它和 Opus 4.5、Gemini 3.0 Pro 的综合分差已经很小。但是结论就是GPT-5.2很好,但代码方面还是看看Opus 4.5吧
如果你每天的核心工作就是写代码、改 Bug、做工程落地,那 Opus 4.5 依然更稳:很多工程类题目里,它通常更容易一次到位,少走弯路。
如果你更看重成本,同时又希望上下文别太短、推理别太弱,那 GPT-5.2 很“好用”:它把价格压得很低,但上下文给得不小,而且在数理推理上很能打(下面会讲怎么理解这些分数)。
如果你经常要处理百万级上下文(比如整本书、超大代码仓库、超长审计材料一口气塞进去),那 Gemini 3.0 Pro 的 1M 上下文依然是最直接的答案。
规格和价格:决定“能不能用得起”的那一刀
很多时候模型差距没你想的那么大,但价格和上下文差距会非常真实地影响你能不能规模化用起来。下面这张表先把三者的关键点放一起(以官方公开的 API 定价与上下文为准;不同渠道/地区/计费口径可能有细节差异)。
| 维度 | GPT-5.2 | Claude Opus 4.5 | Gemini 3.0 Pro (Preview) |
|---|---|---|---|
| 发布时间(按公开版本/快照) | 2025-12-11(gpt-5.2-2025-12-11) | 2025-11 下旬(公开发布) | 2025-11 中下旬(公开预览) |
| 上下文窗口 | 400K | 200K(常见公开规格) | 1,000K(1M) |
| 最大输出 | 128K | (依官方渠道而定) | 64K |
| 输入价格($/1M tokens) | 1.75 | 5.00 | 2.00(≤200K 提示词档位) |
| 输出价格($/1M tokens) | 14.00 | 25.00 | 12.00(≤200K 提示词档位) |
这张表你可以直接这么理解:
Opus 4.5 是“写代码更稳但更贵”;Gemini 3.0 Pro 是“上下文最长、输出也便宜,但你得确认自己的用法和计费档位”;而 GPT-5.2 的位置最像“把价格打下来、同时上下文给够用、推理还不弱”的折中甜点区。([OpenAI Platform][1])
在我们收集到的数据里,GPT-5.2 在数学相关的分数非常夸张:你可以把它理解成——当问题是那种“推一步错一步就全盘崩”的链式推导(复杂公式、约束很多的推理、需要严谨算清楚的题),它更容易稳定地把链条走完,不太容易中途跑偏。([OpenAI Platform][1])
Gemini 3.0 Pro 的体验更像“知识面和推理都很强,而且能一次吃下特别长的材料”:当你是长文档/长对话/大规模上下文驱动的任务(比如把一堆材料塞进去让它做归纳、对照、找冲突),它的优势会更容易被你感知到。([Google AI for Developers][2])
而 Opus 4.5 在工程类题目里常见的感受是“更像一个真的在写代码的人”:它对需求的“工程化落地”会更敏感,比如更愿意补齐边界条件、把改动控制在合理范围、写出更贴近真实仓库的修复方式。这也是为什么很多人做日常开发会觉得它更顺手。([anthropic.com][3])
实测结果
为了测试,我们做了简单的测试,让三个模型针对DataLearnerAI现有的页面做一次重构设计。也许从现有页面重构各家模型似乎都受到原版的风格影响太大了。指令比较简单,原内容不变,重构新页面,浅色系,结果都有点粗糙简单。Opus 4.5稍微好一点,但切换页签展示风格不友好。GPT-5.2的页面信息度感觉好一点,就是有点太素了,简单堆砌的感觉~




不过这个也看个人喜欢,从我们的角度来看,GPT-5.2基本没有啥设计感。
最后一句实话:分数只是参考,自己上手最靠谱
不过话说回来,分数真的只是一个参考。同一个基准里都可能有 bad case,更别说你的真实业务里,数据格式、上下文噪声、工具链、提示词风格都会改变结果。
所以最靠谱的方式还是:拿你自己的 10~30 条真实样本直接跑一遍。简单来说,纯代码场景 Opus 4.5 往往更强;但如果你同时在意成本和上下文长度,GPT-5.2 也完全能打;而超长上下文这件事上,Gemini 3.0 Pro 依旧是独一档。
完整的对比可以参考:https://www.datalearner.com/compare/result?modelInputString=739%2C724%2C707
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
